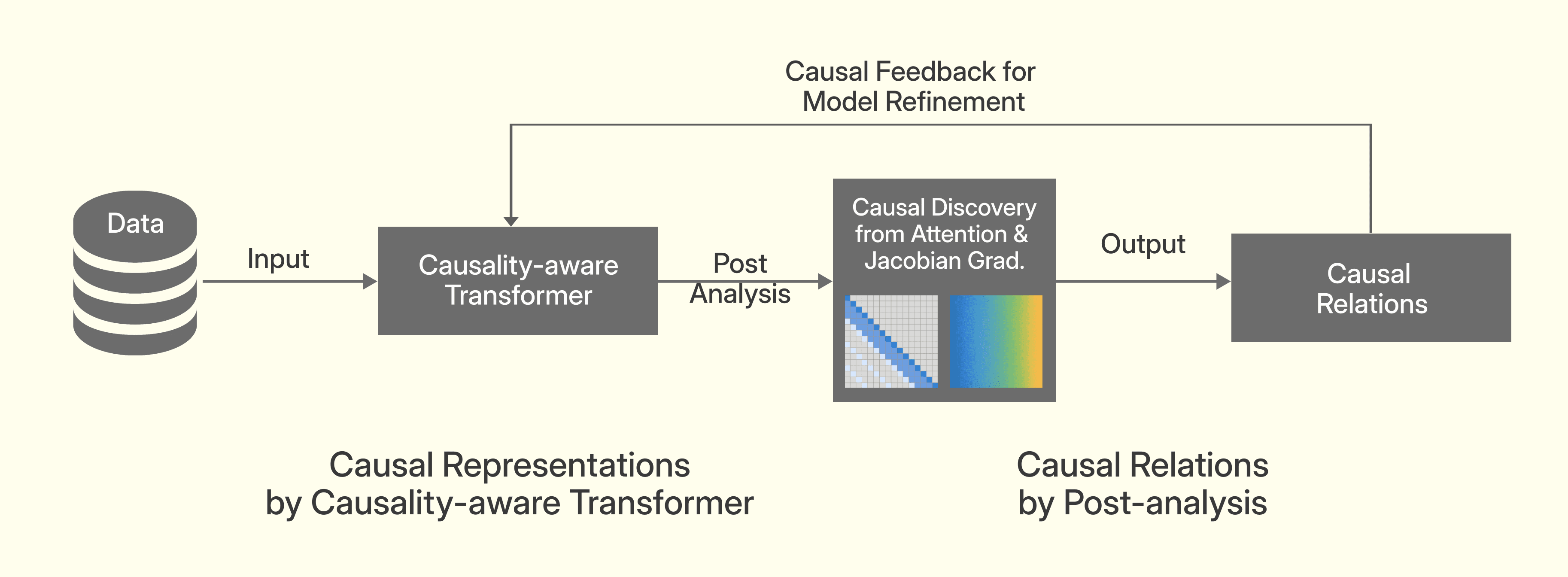
This work proposes LCDM, a large-scale transformer-based causal discovery model that reframes causal learning as a general-purpose inference capability. By fine-tuning pretrained LLMs and performing post-hoc analysis of attention patterns and Jacobian gradients, LCDM reconstructs causal graphs in a zero-shot and scalable manner, eliminating the need for dataset-specific retraining or handcrafted causal modeling.

We are developing a totally novel architecture called Large Causal Discovery Model (LCDM), with the goal of turning causal learning into an inference task—eliminating the need for retraining or hand-crafted modeling for each new dataset, similar to current pre-trained large models.
Moreover, rather than training from scratch, we fine-tune existing LLMs. Since LLMs are trained via next-token prediction, they implicitly learn Markov blankets of variables. We leverage this property and apply post hoc analysis of attention matrices to reconstruct causal graphs.
This approach enables scalable, zero-shot causal reasoning, and transforms causal learning into a reusable capability embedded in the foundation model itself.
© 2026 Abel Intelligence Inc. All rights reserved
System
Platform
Trust
Legal
Community